2024全国大数据与计算智能挑战赛正式开启!
报名网址:https://d2.nudt.edu.cn/tzs/
大数据与决策(国家级)实验室连续三年组织发起全国大数据与计算智能挑战赛,旨在深入挖掘大数据应用实践中亟需破解的能力生成难题,选拔汇聚数据领域优势团队,促进大数据领域的技术创新和面向需求的成果生成,推动形成“集智众筹、联合攻关、共享共用”的研建用一体迭代演进创新模式。
2024全国大数据与计算智能挑战赛以“发榜挑战、集智攻关”为主题,面向全国大数据与计算智能领域的相关单位,围绕自然语言处理、目标识别、图像检测、隐私计算等前沿技术难点开设赛道,以“揭榜打擂”的形式组织创研竞赛,通过线上打榜与现场评审相结合的方式决出优势团队,进一步优化大数据建用模式,推动大数据与计算智能领域技术发展与生态构建。
今年,大赛还与粤港澳大湾区(黄埔)国际算法算例大赛、第三届“金海豚”杯电子水声对抗算法挑战赛等顶级赛事联动,旨在为参赛团队提供更多的发展机会与资源支持,进一步促进技术创新和成果转化,加速培养高水平的人工智能与信息技术人才。
欢迎全国各工业部门、科研院所、各高校及民营企业的业内优势团队踊跃参赛揭榜!
组织结构
组织单位
国防科技大学 大数据与决策(国家级)实验室
大赛召集人
黄宏斌 大数据与决策(国家级)实验室主任
大赛筹划委员会
刘丽华 吴继冰 李璇 陈海文 曾维新 张亮 罗嘉伶
赛题介绍
赛题1:低资源智能传感设备隐私聚合技术
赛题任务:本赛题要求在低资源智能传感设备环境下实现轻量级的隐私保护数据聚合,要求数据密文传输以及聚合匿名保证。为了赛题具备更好的代表性、实用性,赛题选择用于天气预测和跟踪船舶的两个公开数据集——欧洲气象预值数据集和美国海岸警卫队船舶轨迹数据作为测试依据。聚合算法需要适应数据的多维特性,且兼具容错能力,确保即使某些传感设备因故障掉线,也能稳定高效地聚合剩余传感设备的数据。
大赛题2:多文档事件摘要信息生成
赛题任务:现实生活中存在许多持续时间较长的事件,事件的信息分布在多篇相关的文档中。本赛题构建多文档事件摘要数据集并基于该数据集发布多文档事件摘要信息生成挑战,要求根据多个相关的文档围绕关键事件信息生成高质量摘要。为满足快速梳理事件发展脉络的现实需求,要求生成的摘要中事件及事件要素信息、时序关系、因果关系尽可能全面、完整、准确。赛题对长文本理解、事件信息理解以及跨文档的共指消解能力具有较高要求,具有挑战性。
赛题3:基于多源异构融合数据的空间物体识别
赛题任务:本赛题构建空间物体光雷高分辨图像数据集并基于该数据集发布基于多源异构融合数据的空间物体识别挑战,要求准确识别训练集目标,并对训练集外目标完成拒判,为更好助力目标形态确认,要求精确检测空间物体主要部件数量,主要部件包括主体、载荷与帆板。赛题分为互联网初赛、线下复赛和决赛,选用不同数据子集测试,内容相承、难度递增。此外,性能测试将在同一通用计算环境下进行,不能依赖特殊硬件。
赛题4:领域事件多因果关联挖掘
赛题任务:本赛题构建多因果关联事件挖掘数据集,并基于该数据集发布领域事件多因果关联挖掘挑战。参赛者需运用自然语言处理技术,设计高效的算法模型,以独立、准确、完整且高效地从文档中识别出具有因果联系的事件,并提取出因果事件的要素。此外,为更好地探索因果关系的内在产生逻辑,参赛者还需准确判断因果关系的类型。
赛题5:面向大语言模型的领域知识注入与推理
赛题任务:本赛题专注于构建面向特定领域的应急处置规则与实例数据集,并在此基础上推出面向大语言模型的规则知识注入与推理挑战。要求参赛者基于详细的规则知识,进行精准的知识注入,同时使用多样化的实例数据,准确地实现复杂决策场景的推理任务。此外,竞赛中将特别关注规则知识与实例数据间的交互,定义了交织实例的概念,即在同一决策背景中涉及多条规则的实例。本次赛题鼓励参赛者有效识别并处理这些交织实例,确保推理过程的准确性和可解释性。
赛题6:面向联邦学习的数据样本对齐
赛题任务:本赛题构建联邦学习中数据样本对齐功能需求场景并提供数据集,发起面向联邦学习数据样本对齐挑战赛。要求在总共三个参与方、参与方之间输入数据集行数分别为100万、50万和25万的前提设置下运行数据样本对齐,并使所有参与方均得到数据样本对齐结果(即三方数据集的交集结果)。尽可能快速地完成数据样本对齐,保证正常运行数据样本对齐功能后不泄露除了结果以外的任何额外信息,且不出现结果缺项或多项的错误情况。
赛题7:基于对抗场景下重要目标人脸深度伪造视频检测
赛题任务:本赛题构建目标人物的人脸伪造检测数据集并基于该数据集发布目标人物的深度伪造视频检测挑战,要求在数据集中快速、准确地分辨出目标人物和非目标人物,且准确地检测出人物视频是否为深度伪造的。此外,为更好地贴合真实场景、防止信息混淆、误导决策,本次赛题还在视频中添加了互联网上的常见扰动,要求检测模型能够在抵御多种扰动的前提下实现重要目标人物的人脸深度伪造视频检测。
赛题8:基于海量数据的脉冲雷达辐射源型号识别(第三届“金海豚”杯电子水声对抗算法挑战赛联动赛题)
赛题任务:本赛题构建特定时空电子侦察数据片段集合,并基于该数据开展雷达辐射源识别型号识别挑战,要求对于给定的每一个识别数据集,参赛者需要综合运用给定的各种类型侦察数据进行识别,给出数据集中存在的雷达辐射源型号识别结果,本次挑战需要考虑判断待识别样本是否为新目标发射的信号以及积累已有目标的信号数据,待分类的数据中将无可避免的混入已知辐射源个体或未知辐射源个体的噪声样本。
赛题9:基于大语言模型的数据库查询指令生成(粤港澳大湾区(黄埔)国际算法算例大赛联动赛题)
赛题任务:本次竞赛采用独特的数据集,涵盖了跨库查询、多语言环境以及复杂的多轮对话场景,其中对话不仅涉及共指消解、追加询问等上下文依赖关系,还引入了数据库跳变的难题。竞赛的核心在于,参赛队伍需建立出能够理解、解析并转化自然语言查询为精确SQL指令的模型,能够处理对话中不同数据库领域间的无缝切换,要求模型具备极高的泛化能力和领域适应性能力。
赛题10:基于SAR图像的近岸密集小目标船只检测(粤港澳大湾区(黄埔)国际算法算例大赛联动赛题)
赛题任务:本赛题构建了大规模SAR图像船只目标检测数据集,并筛选出了近岸、密集、小样本三类困难样本。基于该数据集发布了船只目标检测任务,对于给出的SAR图像切片测试样本,参赛者需要使用训练的模型正确检测船只目标位置。其中,初赛使用整个测试集,要求选手能够尽量准确地检测船只目标位置,复赛针对近岸、密集、小样本三类困难样本,要求选手能够尽量准确地检测困难样本船只位置,并尽量降低模型参数量、提高推理速度。
大赛赛程共计两个月,采用初赛、复赛、决赛的“三级赛制”,具体赛程安排如下:
初赛阶段
即日起,发布大赛赛题,选手可登录大赛官网报名,第一轮评测开启;
10月28日(12:00),截止报名组队及团队信息修改;
10月30日(24:00),截止初赛作品提交,遴选复赛入围团队。
复赛阶段
11月01日–11月07日,开启第二轮评测,根据赛题设线上和线下两个赛道进行;
11月中旬,反作弊审核、作品成绩复现,遴选决赛入围团队。
决赛阶段
11月底,组织线下专家评审,入围决赛团队现场答辩,适时公布优胜队伍,组织颁奖。
注:
入围决赛团队确定后,决赛团队须指定代表参与现场答辩。
赛程时间与遴选入围数量根据实际情况调整,各赛题赛程有所不同,详见各赛题页面说明。
大赛激励
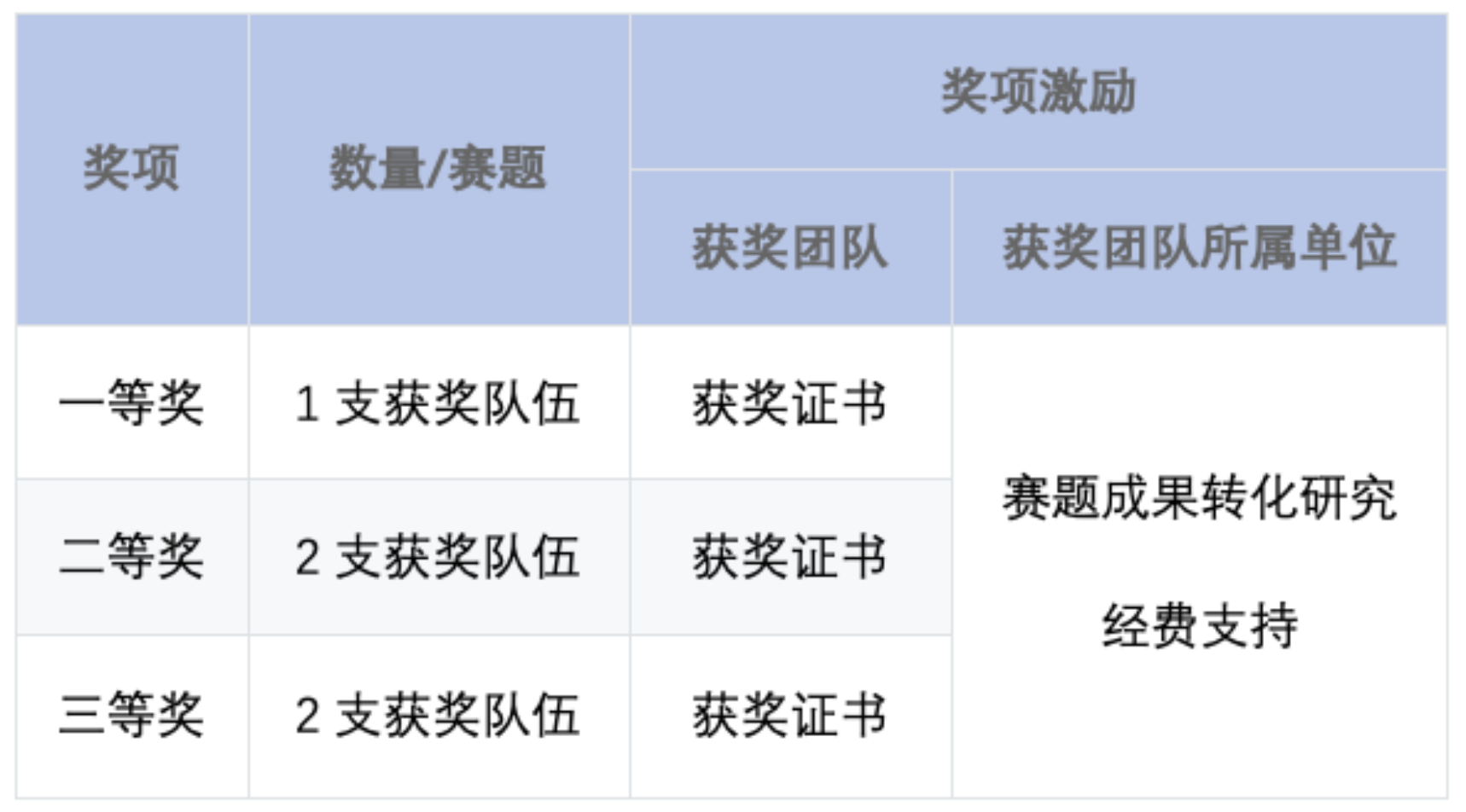
组队安排
前往大赛官网:https://d2.nudt.edu.cn/tzs/

(扫码报名)
参赛对象
面向全国各工业部门、科研院所、高校、民营企业。
报名要求
参赛队须以单位名义实名制报名,同一单位可有多支参赛队。
参赛选手可报名多个赛题,但在同一赛题中仅能报名参加一支团队。
学生参赛者报名须指定至少一名所在单位任职的具有中级职称以上相关领域科研工作者作为团队指导教师。
组队要求
所有报名参加同一赛题的参赛者,可在PC端进行组队操作。
所有参赛选手应在截止日期前自行完成组队,每队1-5人(含指导教师),不可重复组队。选手需以团队身份提交各阶段的作品材料,一旦进入团队,不可退出队伍。
多个单位的参赛者联合组队时,队长所在单位为该参赛队的第一单位。
为保证每支参赛团队享有相对平等的提交机会,各赛题组队需满足组队成员在赛题中的提交总次数≤开赛天数*3次。
队长责任制
各团队队长作为团队的负责人,需自行进行团队内部分工和协调,并承担与大赛组委会对接沟通(包括但不限于晋级入围、团队信息收集、作品审核、线下活动等)的责任。
*详细规则以官网内容为准。
答疑交流
欢迎扫描下方二维码,加入对应赛题交流群,参与赛题答疑和交流讨论。

低资源智能传感设备隐私聚合技术

多文档事件摘要信息生成

基于多源异构融合数据的空间物体识别

领域事件多因果关联挖掘

面向大语言模型的领域知识注入与推理

面向联邦学习的数据样本对齐

基于对抗场景下重要目标人脸深度伪造视频检测

基于海量数据的脉冲雷达辐射源型号识别

基于大语言模型的数据库查询指令生成

基于SAR图像的近岸密集小目标船只检测
如未能成功入群,欢迎联系“运营工作人员”
